どうも、フリーランスでITエンジニアをやっているKerubitoです。
重い腰を上げてそろそろはじめようかと思っています。
そう、AIについてそろそろ学ぼうかと。
ITで飯を食っている者としてこういう新しい分野は積極的に吸収していかないと・・・というのは建前。
「AI覚えたらがっつり稼げるんじゃね!?」
というのが本音です(笑
冗談は抜きにして、効率化がビジネスの需要なキーワードである以上、AIの需要は右肩上がりでしょう。
そうなると当然、AI関連の技術者も必要となります。
今後どのような人材が必要になってくるかは私のような凡人にはわかりかねますが、AIの基礎を知っていても損はないです。
そこで、人工知能プログラミングを学んでみることにしました。
利用したのは人工知能プログラミング学習サービスの「Aidemy」です。
Aidemyとは?
Aidemyはリリースからわずか3ヶ月ほどで1万人超の会員を獲得した人工知能プログラミング学習サービスです。

キャッチコピーが「10秒ではじめる人工知能プログラミング学習サービス」となっています。
こんなこと言われたら、すぐにでもはじめたくなります(笑
これまでだとプログラミングをするには環境構築という苦行が必要でしたが、Aidemyはそんなまどろこしいことは必要なく、ブラウザベースでプログラミングの学習ができてしまいます。
サイトのトップメージを眺めただけで、Aidemyの理念が見て取れますね。
・プログラム初心者でも大丈夫
・数学の知識がなくても大丈夫
・Python初心者でも学習可能
私も含めて、AIに関してど素人な人間からすると心強い言葉です。
学習した結果、業務を行えるレベルに到達できるかは別問題ですが、まずはやってみないと何事もわかりませんしね。
知らない人間からすると「AIはとにかく難しそう」というなんとなくのイメージが先行しがち。
でも、以前知り合いのエージェントから聞いたのですが「現場レベルだとライブラリを使いこなせれば、問題なく業務をこなせる」とのこと。
難しそうで自分には無理、と敬遠していましたが、ある程度基礎さえわかっていれば今なら逆にハードルが低いかもしれません。
ディープラーニング基礎コースをやってみた
サイトのトップページで二つのコースから一つを選択するようになっています。
選べるのは「ディープラーニング基礎コース」と「Python入門コース」です。
よくわからないので、「ディープラーニング基礎コース」を選択。
するといきなりこんな画面が。
「1.1.1 深層学習を体験してみよう」となっています。
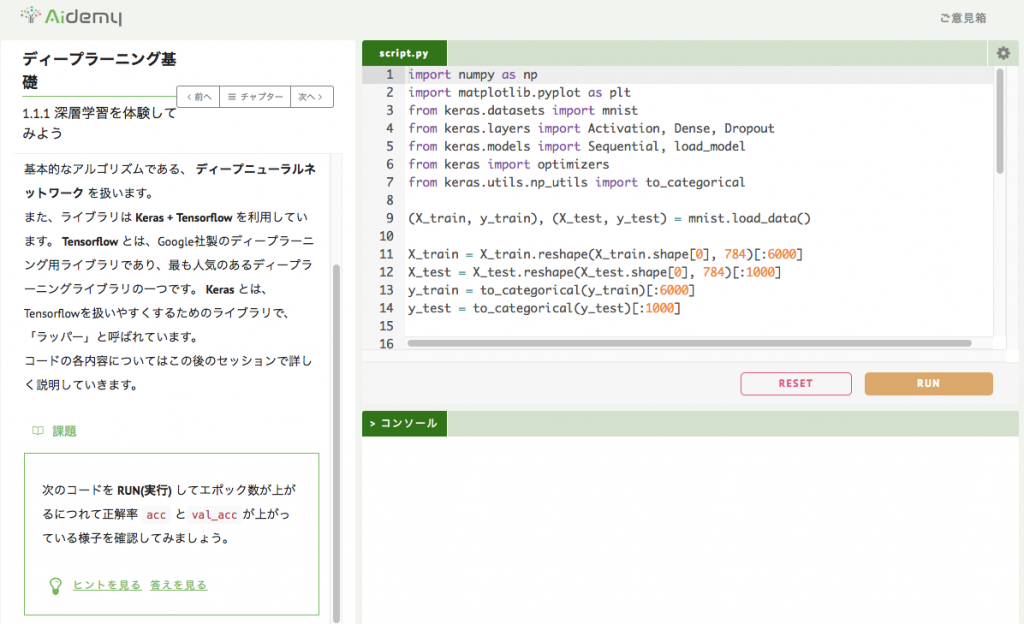
いきなり学習スタートです。
課題が出てきました。
課題:次のコードを RUN(実行) してエポック数が上がるにつれて正解率 acc とval_accが上がっている様子を確認してみましょう。
解説には以下のようなことが書かれています。
解説:
それではこの講座のゴール地点を先に体験してみましょう。
この講座を最後まで受講すると 問題のようなコードを書けるようになります。
今回の講座では、ディープラーニングのなかでも最も基本的なアルゴリズムである、 ディープニューラルネットワーク を扱います。
また、ライブラリは Keras + Tensorflow を利用しています。 Tensorflow とは、Google社製のディープラーニング用ライブラリであり、最も人気のあるディープラーニングライブラリの一つです。 Keras とは、 Tensorflowを扱いやすくするためのライブラリで、「ラッパー」と呼ばれています。
コードの各内容についてはこの後のセッションで詳しく説明していきます。
ディープニューラルネットワークって聞いたことあるな、程度ですね。
ソースはこちら。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | import numpy as np import matplotlib.pyplot as plt from keras.datasets import mnist from keras.layers import Activation, Dense, Dropout from keras.models import Sequential, load_model from keras import optimizers from keras.utils.np_utils import to_categorical (X_train, y_train), (X_test, y_test) = mnist.load_data() X_train = X_train.reshape(X_train.shape[0], 784)[:6000] X_test = X_test.reshape(X_test.shape[0], 784)[:1000] y_train = to_categorical(y_train)[:6000] y_test = to_categorical(y_test)[:1000] model = Sequential() model.add(Dense(256, input_dim=784)) model.add(Activation("sigmoid")) model.add(Dense(128)) model.add(Activation("sigmoid")) model.add(Dropout(rate=0.5)) model.add(Dense(10)) model.add(Activation("softmax")) sgd = optimizers.SGD(lr=0.1) model.compile(optimizer=sgd, loss="categorical_crossentropy", metrics=["accuracy"]) # epochsに5を代入してみましょう。 history = model.fit(X_train, y_train, batch_size=500, epochs=5, verbose=1, validation_data=(X_test, y_test)) #acc, val_accのプロット plt.plot(history.history["acc"], label="acc", ls="-", marker="o") plt.plot(history.history["val_acc"], label="val_acc", ls="-", marker="x") plt.ylabel("accuracy") plt.xlabel("epoch") plt.legend(loc="best") plt.show() |
はじめにゴール地点を示して、ディープラーニングを体感します。
AIといえばPythonで、このソースもPythonで書かれていますね。
Pythonはまったく知らない私、さっそくコースの選択をミスったかもしれません(笑
まあ、その辺りは緩くやっていきます。
この課題の中で「エポック数」が意味不明だったのでググってみました。
エポック数:一つの訓練データを何回繰り返して学習させるか
なるほど。
少なすぎると、正解率は上がりませんし、ある一定回数を超えると正解率は高止まりする、というのはなんとなくわかります。
それではさっそく「RUN」をクリックして実行してみました。
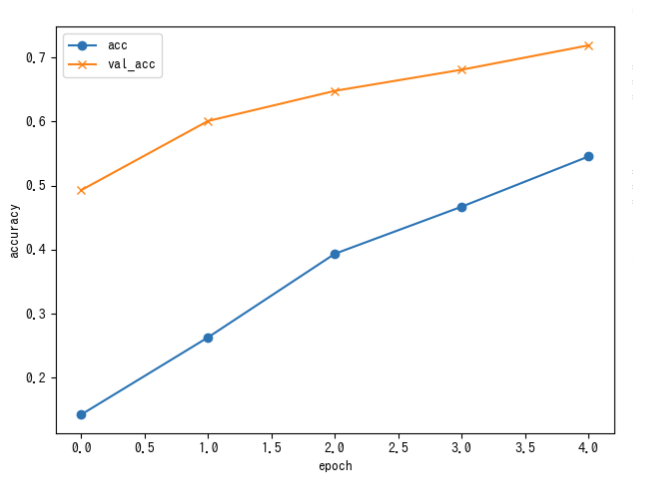
おお!
エポック数が上がるにつれ、正解率の上昇しているのがわかりますね。
やはり実際に動かしてみて、体感するのは大きいです。
試しにエポック数を10に変えてみて実行してみました。
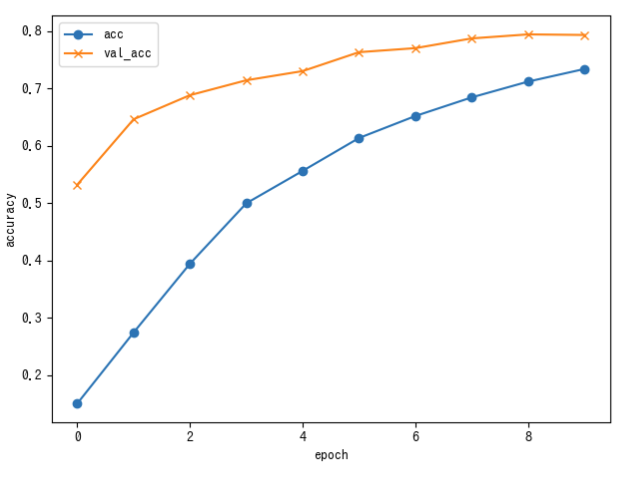
エポック数が5を超えると正解率の上昇率が鈍くなっているのがわかります。
Pythonがわからなくてもなんとなくやっていることは想像できるのですが、ディープラーニングの基礎、お作法をわかっていないので、体系的に頭の中には入ってきませんね。
これ以降のチャプターでディープラーニングの基礎から学んでいけます。
まとめ
まだ入口の門をくぐった程度ですが、少し触っただけでも面白かったです。
っていうか、かなり楽しいかも・・・。
細かいことはわかりませんが、AIを使えば様々なものに応用できるかもしれないという可能性を感じられただけでも、やってみた価値はありました。
「AIを利用できるエンジニア」というだけでも、今後需要は大いにありそうですしね。
その学習を後押ししてくれるAidemyは素晴らしいサービスだと思います。
